
{kind=link}
We are pleased to announce that btcd, our full-node bitcoind alternative written in Go, is finally ready for public testing!
The installation instructions and source code can be found on github at:
https://github.com/conformal/btcd
A Brief History
Back in May, we first announced our plans to release btcd. A week later we released our first core package from btcd, btcwire, and announced our plans to continue releasing the component packages of btcd in a staggered fashion.
Over the next month, we released btcjson, btcdb, and btcscript. Then in mid-July we released btcchain at which time we announced btcd was next. At that point, btcd had most of the core bits and we figured we’d be releasing it within a few weeks. Well, as you have no doubt noticed, it is now 10 weeks later…
What Took so Long?
As typically happens with development, several things came up, all of which took a few days (or a week) here and there.
The following list is a brief overview of the various things that were tackled:
- Decided to separate chain and wallet architecture
- Added built-in support for the “official” bitcoin block acceptance regression test
- Added support for testnet
- 3 separate issues with the Go run-time garbage collector leaking memory
- Extremely poor SQLite performance
- Provided LevelDB as another backend database written in pure Go instead of requiring cgo like SQLite
- Worked with the goleveldb author to identify and squash several bugs
- Added support for proxies and tor (including proper DNS resolution via tor to avoid leaking your IP)
- Implemented complete address manager including bucketizing to increase geographic separation and reduce attack vectors
- Finished the connection manager which deals with talking to multiple peers simultaneously
- Implemented a transaction pool and relay complete with proper chain rule adherence and additional filtering for miners
So, as you can see from the list above, we were able to cram quite a bit in 10 weeks!
Separate Chain and Wallet
While implementing the wallet and starting to build the GUI, we quickly realized that there is, what we consider, a fundamental design flaw in the other implementations we have seen to date. In particular they have the wallet and chain functionality integrated in the same process.
It certainly makes the code significantly easier to work with when chain and wallet code can be intermingled without having to deal with IPC, as we were originally going to do, but that design has several issues, some of which will be covered in the next section. Rather than simply taking the easy way out to get something out quickly, we decided to go back and spend the time necessary to split the chain from the wallet.
Why Separate Chain and Wallet?
One of the major problems with wallet and chain functionality integrated in the same process is multi-user support. For example, when using bitcoind or bitcoin-qt, two users sharing the same computer must each maintain their own block chain. This results in duplicated effort and wasted disk space, as the block chain is public data and should be sharable. Due to this, btcd is designed to provide chain services for separate wallet processes. These processes then are able to request updates to the chain and submit transactions to the network without having to deal with all the complexities of chain management.
Multiple devices and thin wallets can also be supported based on this design. In future versions of btcd, wallet communication will occur over HTTPS connections using websockets. Separate wallets sharing a single chain are not limited to multiple users on just a single computer. Multiple users, each with their own devices and wallets, can authenticate and connect to a shared btcd server. Because the hardware requirements for every additional wallet are so small, old hardware which is not capable of handling the computing needs of full-node validation can be re-purposed.
There are some other benefits which will be covered in an upcoming blog post on btcwallet, the wallet implementation which works with btcd to provide wallet services.
What about the cons?
- Slightly more difficult to configure for a single user that will only ever be using a single machine (increasingly less common these days)
- Increased complexity during the testing process, as separate binaries must be tested while executing at the same time
- SCM tools like ‘git bisect’ may not be to able locate when and how a bug was introduced as easily
Architecture Overview for btcd
The following diagram depicts the internal architecture of btcd as well as how all of the bitcoin related packages we have released fit together:
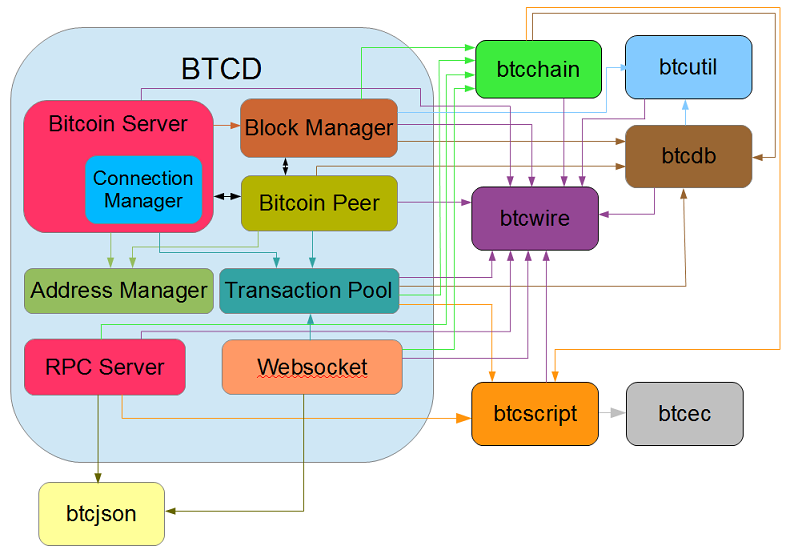
btcd Architecture Overview
Regression Test
btcd has built in support for the “official” bitcoin block acceptance regression test. The following screenshot shows the results of running the regression test against btcd. As you can see, the regression test tool thinks it’s talking to bitcoind, but it’s really talking to btcd. The highlighted lines show that the block acceptance behavior of all tested cases is the same between btcd, bitcoind, and bitcoinj.
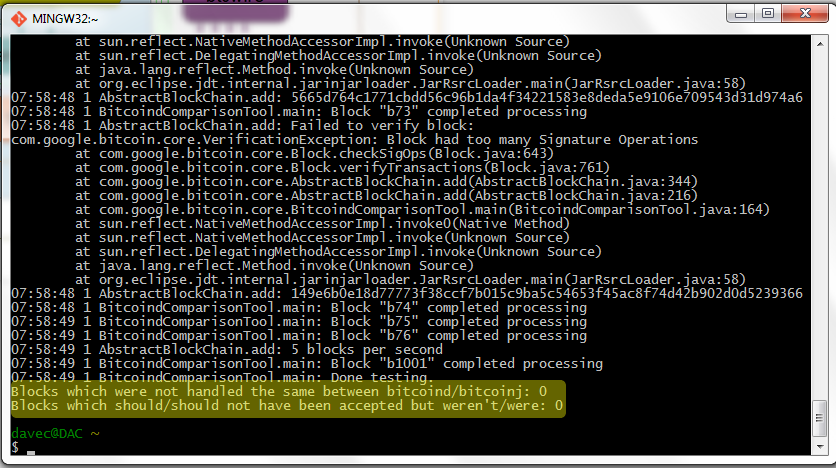
What’s Next?
We are looking for early adopters to help us test btcd. So, if you’re interested, check out the installation instructions here.
One of the outstanding issues is the ECDSA cryptography provided by the Go standard library is extremely slow. There are some significant improvements in the upcoming Go 1.2 release, but even with those improvements, it is still orders of magnitude slower than OpenSSL.
On the btcd front in the near term, we are going to continue development to complete some of the remaining unfinished items in the code, improve the documentation, and address issues as they arise. A longer term goal is to work on optimizing the cryptography.
Our next planned software release is btcwallet. It is the separate wallet process we have been developing alongside btcd for wallet functionality. More details regarding this software will be announced soon in an upcoming blog post.
Awesome work! This will be so good for the ecosystem. I saw your talk at the conference and am very glad to see it released.
Thanks for your comments, Andrew. We’re excited too!
Can you elaborate on the SQLite performance problems and how you dealt with them? Which driver were you using?
Hi John,
The core of the issue is simply the huge amounts of records necessary to store a full transaction index. As of this moment, there are ~24.5 million transactions in the block chain and it will continue growing rapidly. Inserting records into a table with an index when the table has millions (let alone 10s of millions) of records is painfully slow with SQLite.
You might already be aware how the transactions link together, but I’ll give a quick explanation for everyone reading. A Bitcoin transaction consists of a bunch of inputs and outputs (and a couple of other fields not really relevant to this discussion). The inputs reference a previous transaction output by what’s called an outpoint. Each outpoint consists of the hash of the previous transaction (which is treated like a unique ID), as well as the specific index of the output in that transaction.
Part of verifying that a new transaction is valid, and the spender owns the coins they are attempting to spend, requires looking up and using data from the old transaction that is being referenced from the inputs of this new transaction. So, the trick is that you have to quickly be able to fetch these old transactions given their hash (ID). This basically means you either maintain a transaction index which you can use to match a transaction hash against the block it’s contained in (and the offset into the block) or you scan the entire blockchain (typically backwards as referenced transactions outputs are usually much closer to the end than the front of the chain) for every lookup. We opted for the former.
Since the hash is the unique ID used to lookup a transaction, you basically require a SQLite index against the field for fast querying. This brings us full circle to the issue of extremely slow insertion into indexed tables with millions of records.
So, what we basically did to improve the issue is use a two table approach. We insert transactions into temp transaction table until it reaches a certain number of transactions (which is less than the point performance really starts tanking), then go through a db compaction phase where we disable and remove the index on the main transaction table, migrate all of the transactions from the temporary table into the primary table, vacuum (compact) the database, then recreate and enable the index on the primary table.
It’d be apt to just refer to this as “not your average bitcoin daemon,” the implication at the moment being that no mother can make sensible technical decisions (concerning bitcoin systems, at the very least).
Some libraries of Go are kinda slow currently and that may cause some performance problems in this bitcoin client. It will change a lot in Go 1.2 especially the network part. Any way, you have been done good job.
Thanks for your post. Overall, I’m really pleased with the performance. The biggest performance issue is the cryptography. The SQLite performance, as I elaborated on a above, has much more to do with just the shear amount of data as opposed to any issues with Go.
Good job. Can you explain a bit about how btcwallet cope with the file wallet.dat? If my wallet.dat is encrypted, can I transfer coins via btcd & btcwallet?
Hi. I’m implementing btcwallet so I’ll try to answer your questions.
We are not using the same wallet format on disk as bitcoind or bitcoin-qt (wallet.dat) and do not at the moment have any tools written to convert between formats. Our wallet file is most similar to the format the Armory client uses, although additional files are also needed to save records of unspent transaction outputs.
One area where btcwallet differs from Armory is that we only support encrypted wallets (where encryption is limited to your private keys, everything else is clear text). Creating a transaction in wallet and sending it off to btcd to relay to the Bitcoin network requires your wallet to be unlocked, which is done by using the ‘walletpassphrase’ command (part of the standard RPC Bitcoin API).
Hopefully that helps!
Thank you for reply! I am new to Bitcoin(about half a year) and interested in it. And I am running a bitcoin based SNS http://zillat.com/ but currently only Chinese version on it.
I will try my best to understand your codes. Thanks!
I tried it with testnet. Works great! However, it took a while to sync though (couple of hours – ran the daemon connected to a single peer (local bitcoind instance)). The codebase is impressive. Well structured and easy to read.. especially when compared to the source of Satoshi client. Thanks a lot for this!
Will you guys be implementing websocket-based notifications? From a quick look at the code, I figured I could probably, temporarily, modify mempool.go (for tx notifications) and process.go (for block notifications). Is a feature like this on the cards? Also any ETA on the completion of the remaining RPC commands?
Thanks again for giving this wonderful alternative to bitcoind!
Thanks for your comments.
Yes, websocket-based notifications are under development. In fact, btcwallet bits make use of them which is why they’re on the architecture diagram I made in the post. They just aren’t public yet, but will be once things stabilize a bit. On the notifications, yes it would be possible to temporarily modify the code in the sections you pointed out. I believe I put TODO comments where the notifications should go in the code.
The remaining RPC calls are about 4th down on the list, so I’m not sure exactly on a time frame yet as it depends on how long the other ones take. Releasing btcwallet is higher priority right now for us than the RPC calls, so I would guess something like 3-4 weeks. Don’t hold me to that though as it could go either way depending on what issues arise!
Are there any RPC calls in particular you are after first? When we start implementing them, we can prioritize the specific calls depending on the desire of the community.
I tried again today. Surprisingly it fails to load the db. Get this error:
➜ ~GOPATH ./bin/btcd -C /Users/shripadk/Bitcoin-btcd/bitcoin.conf
[21:02:27 2013-10-12] [INF] [BTCD] [BMGR] Loading block database from ‘/Users/shripadk/.btcd/data/testnet/blocks_leveldb’
[21:02:27 2013-10-12] [ERR] [BTCD] unexpected EOF
Here is the log output. Any idea why the db got corrupted?
➜ ~GOPATH cat ~/.btcd/data/testnet/blocks_leveldb/LOG
=============== Oct 12, 2013 (IST) ===============
21:04:41.482844 db@open opening
21:04:41.483848 journal@recovery F·1
21:04:41.483859 journal@recovery recovering @2791
21:04:41.484765 journal@drop journal-2791 S·104B “length overflows block”
I was going to suggest you put this on github, but I see you already have. I’ll speak to it over there.
Edit: For reference to anyone reading, this issue was resolved: https://github.com/conformal/btcd/issues/18
I’m testing this out and I see that btcd is not using 100% CPU for the initial blockchain download.
I shouldn’t be IO bound with the setup I’m using, so is this just one of the crypto libraries not using all my cores effectively?
The real crypto doesn’t kick in until after the final checkpoint, which as of 0.3.3-alpha is at block height 267300.
What you are seeing is that in order to do full node validation of a block, each of the input transactions for every transaction in a block have to be looked up (and each transaction can have multiple inputs). So, take for example, block 180,000 (http://blockexplorer.com/b/180000). It has 235 transactions in it, but those transactions reference something like 425 transactions. The further in the block chain you go, the larger these numbers get.
So basically, you are IO bound looking up all of the input transactions, then CPU bound for the validation, and it goes back and forth. If you monitor your usage you should notice this pattern.
Note that there is certainly some potential to pipeline this better that we have discussed where you start validation on the pieces you have already versus waiting for the entire lookup, however, preliminary tests have shown it doesn’t make a huge difference due to how slow disk is compared to CPU.
Does this support bootstrap.dat?
Is that database footprint much larger than with the “standard” bitcoind? (I bought a 60GB SSD, hope is will last a year or two).
The bootstrap.dat file is supported via a separate utility named addblock. We generally prefer to add features such as importing bootstrap.dat and initiating RPC commands through separate utilities as opposed to the bitcoind model of putting everything into the daemon.
The database footprint is nearly identical since they essentially contain the same information in the end. One thing to note is bitcoind does not do transaction indexing by default whereas btcd does, so if you compare the defaults in both cases, you’ll notice the btcd database is slightly larger. However, if you turn on transaction indexing in bitcoind (-txindex I believe is the flag), you’ll see they’re extremely close.
I would be interested what are your thoughts on optimizing the ECDSA code in Go – would calling to C implementation help? Has performance improved since Go 1.2?
Thanks